一、创建模型 1.1 需求分析 为了方便演示,我们先来构造一下需求场景。现在有这么四张表,分别是:
Book表 用于记录书籍的书名,价格,作者,出版社等信息
Author表 用于记录作者的简要信息以及编写的书籍的相关信息
AuthorDetail表 用于记录作者的详细信息
Publish表 用于记录出版社的信息和出版书籍的相关信息
我们再为上述的四张表添加以下的对应关系:
一对一 每一条作者的简要信息都会有且仅有一条详细信息对应,即 Author表和AuthorDetail表是一对一的关系
一对多 一个出版社可以出版多本书籍,但是一本书籍不能由多个出版社联合出版,即Book表和Publish表是一对多的关系
多对多 一本书可以由多个作者联合编写,一个作者也可以编写多本书,即Book表和Author表是多对多的关系
在 SQL 中,对于一对一的关系,只需要通过一个关联字段即可将两张表进行关联;对于一对多的关系,我们需要通过外键来将两张表进行关联;对于多对多的关系,我们需要通过第三张表来作为中间表进行关联,而在 ORM 中,我们也可以通过上述方式来对多表做关联操作,但是 ORM 还为我们提供了更简单的方式,如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 from django.db import modelsclass Book (models.Model):True )32 )5 , decimal_places=2 )"Publish" , to_field="nid" , on_delete=models.CASCADE)"Author" )class Author (models.Model):True )32 )"AuthorDetail" , to_field="nid" , on_delete=models.CASCADE)class AuthorDetail (models.Model):True )10 )class Publish (models.Model):True )32 )32 )
执行数据库迁移操作
1 2 python manage.py makemigrationspython manage.py migrate
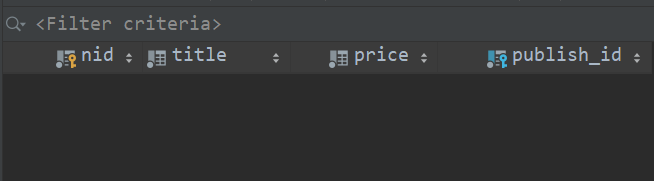
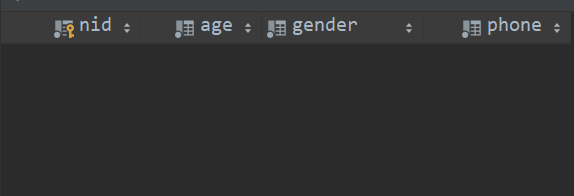
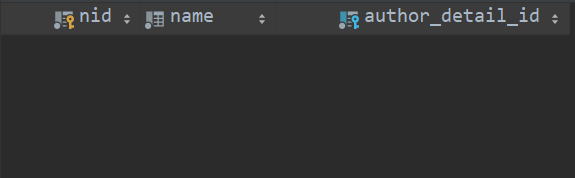
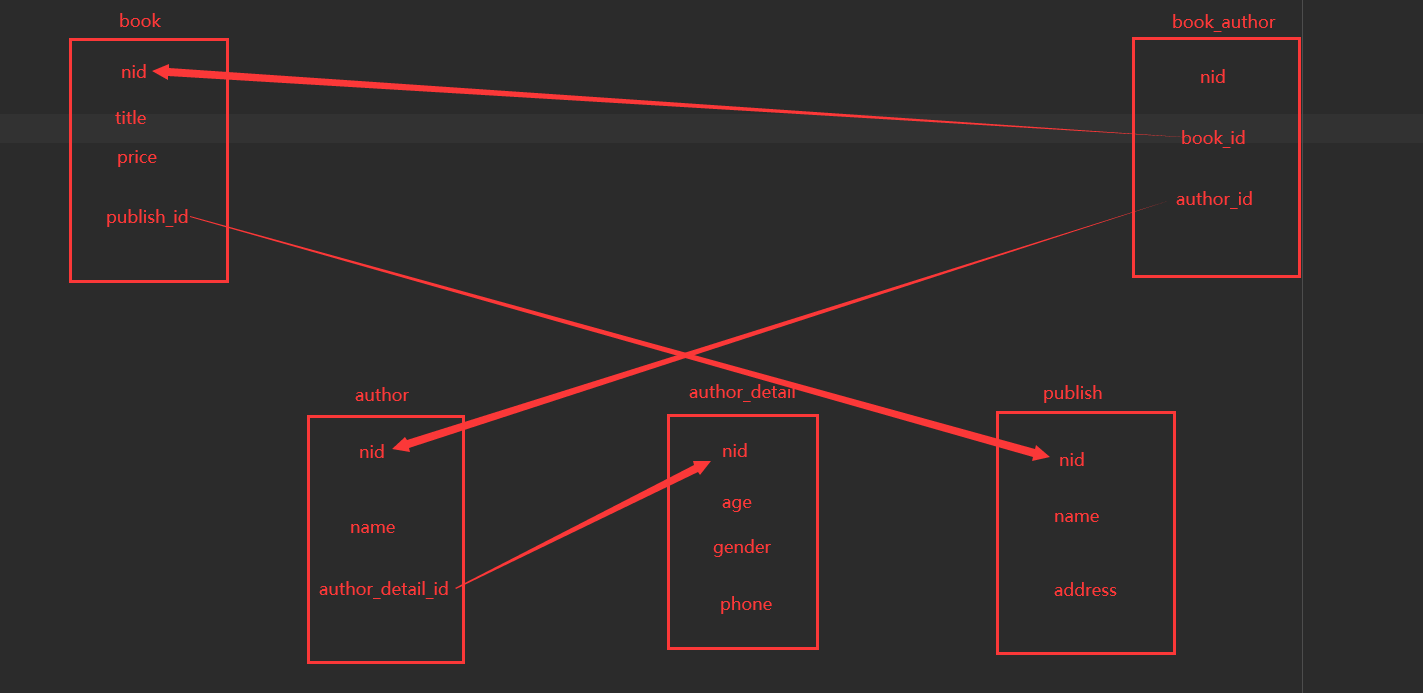
此时我们可以看到在数据库中多出来五张表,且表中对应的字段分别如下:
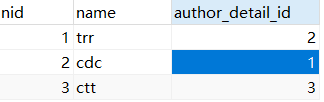
对于 publish 表和 author_detail 表没有什么特别的地方,和我们在模型中定义的字段是一样的。对于author表,我们并没有看到在 Author模型中定义的一对一的关联字段 author_detail,反而多了一个author_detail_id 的属性,这是因为对于一对一的表关系,django 的 ORM 机制会把我们定义的关联字段自动加上 “_id” 后作为一个属性,存储在表中,该属性指向的就是关联表的 nid 属性。
同样的,对于一对多的外键关系,django 的 ORM 机制也会把我们定义的外键字段加上 “_id” 后作为一个属性,存储在表中,该属性指向的也是关联表的 nid 属性,即 book 表中的 publish_id 属性字段就是这么由来的。
最后,对于 book 和 author 这种多对多的关系,ORM 自动生成了第三张表来对两者的关系进行管理,表名就是这两张表的名字,中间加上下划线。表中的属性字段 book_id 和 author_id 分别对应book 表和 author 表中的 nid 字段。以上表关系的具体对应关系如下:
补充说明:
对于一对一的表关系,关联字段无论写在哪个模型中都行,因为本质上一对一的表是完全可以合并成一张表的;而对于一对多的表关系,关联字段必须定义在多的那个模型中,如 Book 和 Publish 中,一个 publish 可以对应多个 book,多以外键字段写在了 Book 类中;最后对于多对多的关系而言,关联字段无论写在哪个模型中都可以。
1.2 正向查询与反向查询 正向查询是指,从含有关联属性的表去跨表查询对应的表的过程;反向查询是指从其他表跨表查询含有关联属性的表的查询过程。举个例子,就 book 表 和 publish 表,在 book 表中定义了外键关联字段 publish,此时从 book 表出发去 publish 表中查询对应数据的过程就是正向查询,从 publish 表出发去 book 表中查询对应的数据的过程即为反向查询。
这里简单介绍正向查询和反向查询的概念,是因为在 ORM 中,正向跨表查询和反向跨表查询的方式是有区别的,我们会在下面介绍查询时具体研究。
二、添加记录 对于一对一的表关系来说,插入数据和单表的插入方式没有任何区别,只需要注意关联字段的值必须能在关联的表中找到对应的匹配值即可。因此我们可以简单的先来为 author,author_detail 和 publish 表插入一些数据,我们重点研究的是一对多和多对多的表关系的数据插入方式。
2.1 一对多插入 2.1.1 通过模型对象插入 1 2 3 "北京出版社" )"跟我学Python" , price=100 , publish=publish_obj)
该方式是通过模型中定义的关联字段来实现数据插入的。首先查询到对应的出版社对象,再将出版社对象赋值给Book模型中定义的外键字段,此时 ORM 引擎会自动去 book 表关联的 publish 表中匹配这个publish_obj 对象,找到这条数据后将该数据对象的 nid 的值赋给 book 表中的 publish_id 属性字段。
2.1.2 直接给 book 表绑定 publish_id 1 2 "跟我一起学GoLang" , price=200 , publish_id=1 )
该方式等价于直接对 book 表进行操作,给表中对应的每个字段赋值。
2.2 多对多插入 1 2 3 4 5 6 7 8 9 "跟我一起学Linux" , price=150 , publish_id=2 )"cdc" )"trr" )
也可以通过指定主键的方式进行直接绑定
1 2 3 book_obj = Book.objects.get(title="跟我学Python" )1 , 2 , 3 )
补充:
1 2 3 book_obj.authors.remove() set ()
三、跨表查询 3.1 基于对象的跨表查询(子查询) 3.1.1 一对一查询 1 2 3 4 filter (name="cdc" ).first()print (phone)
1 2 3 filter (phone=13169857456 ).first()print (per.author.name)
3.1.2 一对多查询 1 2 3 4 filter (title="跟我学Python" ).first()print (book.publish) print (book.publish.name)
1 2 3 4 5 6 filter (name="北京出版社" ).first()all ()for book in books:print (book.title)
3.1.3 多对多查询 1 2 3 4 5 6 filter (title="跟我学Python" ).first()all ()print (author_list)for author in author_list:print (author.name)
1 2 3 4 5 filter (name="cdc" ).first()all ()for book in book_list:print (book.title)
3.2 基于双下划线的跨表查询(join查询) 基于双下划线的跨表查询,其本质是连表查询。正向查询主要通过在表中定义的关联字段来通知 ORM 引擎去 join 对应的关联表,然后进行连表查询;反向查询主要通过小写的表名来告诉 ORM 引擎,让当前表去 join 对应的表,然后进行连表查询。
3.2.1 一对一查询 1 2 3 filter (name="cdc" ).values("author_detail__phone" )print (phone)
1 2 3 filter (author__name="cdc" ).values("phone" )print (phone)
3.2.2 一对多查询 1 2 3 filter (title="跟我学Python" ).values("publish__name" )print (pub_name)
1 2 3 filter (book__title="跟我学Python" ).values("name" )print (pub_name)
3.2.3 多对多查询 1 2 3 filter (title="跟我学Python" ).values("author__name" )print (authors)
1 2 3 filter (book__title="跟我学Python" ).values("name" )print (authors)
练习:连续跨表查询
1 2 3 filter (author__author_detail__age__gt=25 ).values("title" , "publish__name" , "author__name" )print (res)
四、聚合和分组查询 4.1 聚合查询 ORM 中的聚合查询是通过 aggregate() 方法实现的,aggregate() 是 QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典,不再是queryset。键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from django.db.models import Avg, Max, Min, Countall ().aggregate(Avg("price" )) all ().aggregate(average_price=Avg("price" )) all ().aggregate(max_price=Max("price" ))print (max_price)all ().aggregate(min_price=Min("price" ))print (min_price)all ().aggregate(book_num=Count("title" ))print (book_num)
如果你希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数
1 2 res = Book.objects.all ().aggregate(max_price=Max("price" ), min_price=Min("price" ), average_price=Avg("price" ))print (res)
4.2 分组查询 ORM 中的聚合查询是通过 annotate() 方法实现的,annotate()为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数),返回值依然是一个queryset
4.2.1 单表分组 1 2 3 4 5 id name age salary dep1 cdc 12 2000 销售部2 ctt 22 3000 人事部3 trr 22 5000 人事部
我们要查询每个部门有多少人
1 2 # SQL select dep,Count (* ) from emp group by dep;
1 2 3 4 5 from django.db.models import Avg, Max, Min, Countall ().values("dep" ).annotate(Count("name" ))print (res)
values 中存放要分组的条件(需求中是按部门分组),annotate 中存放计算结果,结果的键名默认值为计算的字段加双下划线加计算方式,当然我们也可以指定结果名称
1 2 res = Emp.objects.all ().values("dep" ).annotate(people_num=Count("name" ))print (res)
4.2.2 多表分组 1 2 3 # 查询每个出版社的名称以及对应的出版的书籍量SQL 先连表,后查询select publish.name,Count (* ) from book left join publish on book.nid= publish.id group by publish.id
1 2 3 4 5 6 from django.db.models import Avg, Max, Min, Countall ().values("name" ).annotate(book_num=Count("book__title" ))print (res)
或者还可以这么写
1 2 all ().values("nid" ).annotate(book_num=Count("book__title" )).values("name" , "book_num" )
1 2 all ().values("nid" ).annotate(author_num=Count("author__name" ))
总结:多表分组查询模型:
1 表模型.objects .all ().values ("主键" ).annotate (聚合函数(关联字段__统计字段))
1 后表模型.objects .all ().values ("主键" ).annotate (聚合函数(关联表名__统计字段))
**补充:**当我们不指定分组的依据时,ORM 引擎默认根据主键来分组;
我们还可以查询到分组模型对象的其他字段。
1 2 3 4 "nid" ).annotate(c=Count("book__title" )).values("name" , "address" ) all ().annotate(c=Count("book__title" )).values("name" ,"c" ,"address" ) "book__title" )).values("name" ,"c" ,"address" )
五、F查询和Q查询 5.1 F查询 在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
1 2 3 4 from django.db.models import Ffilter (commnet_no__lt=F('keep_no' ))
Django 还支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
1 2 3 filter (commnet_no__lt=F('keep_no' )*2 )
修改操作也可以使用F函数,比如将每一本书的价格提高30元:
1 Book.objects.all ().update(price=F("price" )+30 )
5.2 Q查询 filter() 等方法中的关键字参数查询其实都是一起进行 AND 操作 的。如果你需要执行更复杂的查询(例如 OR ),你可以使用 Q 对象。Q对象可以使用& 和| 操作符组合起来。当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象。
1 2 3 4 from django.db.models import Qfilter (Q(title__startswith='Py' )|Q(title__startswith='Li' ))
可以组合使用 & 和 | 操作符,以及使用括号进行分组来编写任意复杂的Q 对象。同时,Q 对象可以使用 ~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询:
1 2 3 filter (Q(author__name="cdc" ) & ~Q(publish_date__year=2017 )).values_list("title" )
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将”AND” 在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。例如:
1 2 3 filter (Q(publishDate__year=2016 ) | Q(publishDate__year=2017 ), title__icontains="python" )