一、Web服务的本质 1.1 软件开发架构
C/S架构,即客户端和服务器B/S架构,即浏览器和服务器
从本质上来说,B/S架构 也是 C/S架构 ,只是使用浏览器作为了客户端。
1.2 浏览器的工作流程 当我们在浏览器窗口输入一些小网址并进行搜索的时候,中间到底发生了哪些事情呢?站在宏观的角度去研究,从输入网址到看到我们访问的内容,整个过程中浏览器的工作流程大致可以分为这么几步:
浏览器朝服务端发送请求
服务端接收请求(例如:访问百度首页)
服务端返回对应的响应(例如:返回百度首页的内容)
浏览器接收响应并根据特定的规则渲染页面展示给用户
1.3 模拟一个服务端 以上介绍的流程,其实就是大多数web服务的基本操作流程。我们可以通过套接字编程来编写一个服务端模拟上述过程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import socket"127.0.0.1" , 8080 ))5 )while True :1024 )print (data) b"hello, old baby ~" )
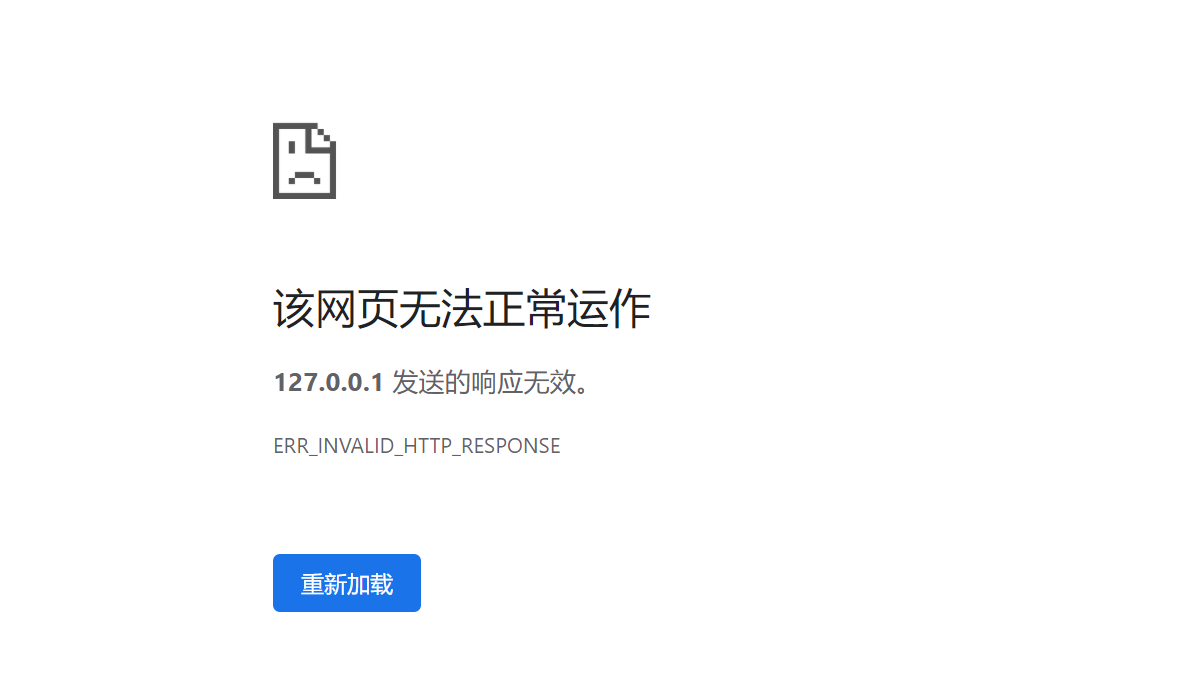
我们不需要再去写一个客户端,可以直接通过浏览器访问服务端的地址和端口来实现通信,因为浏览器本质上就是一个客户端。我们启动服务器,在浏览器输入 127.0.0.1:8080 进行访问:
操作了一把可以看到,实际的结果并没有和我们预期的一样。那么可能有的金针菇就要开始怀疑了,是不是之前介绍的那些理论是有问题的?其实并非如此,我们先来看一下服务端的情况:
很显然,服务端已经接收到客户端(即浏览器)发出的请求了。我们再回过头来观察一下浏览器的报错,127.0.0.1 发送的响应无效,这就表明我们的请求确确实实发送给了服务端,服务端也给了客户端响应,只不过在浏览器这边渲染不出来而已。
1.4 HTTP协议的引入 既然知道了交互失败的原因,那么我们简单来推导一下问题的根源。和我们手写的客户端不同,浏览器可以充当很多服务器的客户端(如百度、腾讯视频、优酷视频……都可以通过浏览器来访问),每个服务端的写法都不相同,浏览器要是想兼容所有的服务端,必须做到以下两点之一:
浏览器非常牛掰,能够自动识别不用的服务端做不同的处理
制定一个统一的标准,如果你想让你写的服务端能够和客户端之间做正常的数据交互,就必须遵循一些规则
显然相比第一点,第二点实现起来就容易的多。而需要遵循的规则,就是我们常说的 HTTP协议
二、HTTP协议介绍 2.1 什么是 HTTP 协议 HTTP 协议(超文本传输协议)是用来规定服务器和浏览器之间数据交互的格式的一种规则协议,该协议你可以不遵循,但是相对的你写的服务端就不能被浏览器正常访问。(当然也可以自己编写客户端,让用户下载 App 进行安装使用)
2.2 HTTP 协议的特性 2.2.1 基于请求响应 服务端只用在接收到客户端的请求后才会去和客户端响应交互,不会主动向客户端交互。
2.2.2 基于 TCP/IP HTTP 协议是基于底层的 TCP/IP 协议,作用于应用层之上的协议。
2.2.3 无状态 不保存用户信息,即不会记录用户是否来访问过,即使同一个用户来访问了多次,每次都会把该用户当成新用户。正是由于该特性,所以后续出现了一些专门用来记录用户状态的技术,如 cookie、session、token 等等。
2.2.4 无/短链接 客户端请求一次,服务器就响应一次,之后两者就断开链接,没有任何联系。
补充 :使用 websocket 协议可实现长链接,即双方建立链接后默认不断开。
2.3 请求数据格式 基于 HTTP 协议通信时,客户端请求数据的格式主要由下面四个部分构成:
2.4 响应数据格式 基于 HTTP 协议通信时,服务端响应数据的格式主要由下面四个部分构成:
**补充:**响应状态码是指用一串简单的数字来表示一些复杂的状态或者描述信息,例如:404:请求资源不存在。常见的状态码主要有以下几种:
1XX:服务端已经成功接收到数据正在处理,客户端可以继续提交额外的数据2XX:服务端成功响应了客户端想要的数据(例如:200 OK请求成功)3XX:重定向(浏览器跳转访问其他非目标页面)4XX:请求错误(例如:403 当前请求不合法或者不符合访问资源的条件)5XX:服务器内部错误
2.5 根据HTTP协议优化自定义框架 在简单了解了 HTTP 协议之后,我们也能很容易的分析出之所以我们自己写的服务端无法和浏览器交互,就是因为我们返回的响应数据格式不符合要求,所以我们只需要做以下修改:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import socket"127.0.0.1" , 8080 ))5 )while True :1024 )print (data) b"HTTP/1.1 200 OK\r\n\r\n" )b"hello, old baby ~" )
启动服务端代码,再次通过浏览器访问 127.0.0.1:8080
我们再来详细看一下服务端收到的请求数据是否符合HTTP协议的请求数据格式:
三、识别路由 1 2 3 4 5 6 7 8 https://www.cnblogs.com/TheGCC/p/14610191. html14644542. html14624524. html14610191. html14644542. html14624524. html
我们访问上述网址时,其实都是在访问同一个服务器,即 https://www.cnblogs.com,但是我们却能看到不同的内容,这是由于每个网址(路由/URL)都有着自己独特的后缀,服务端会根据后缀进行分析,做出不同的响应,我们也可以给我们的框架添加此功能。
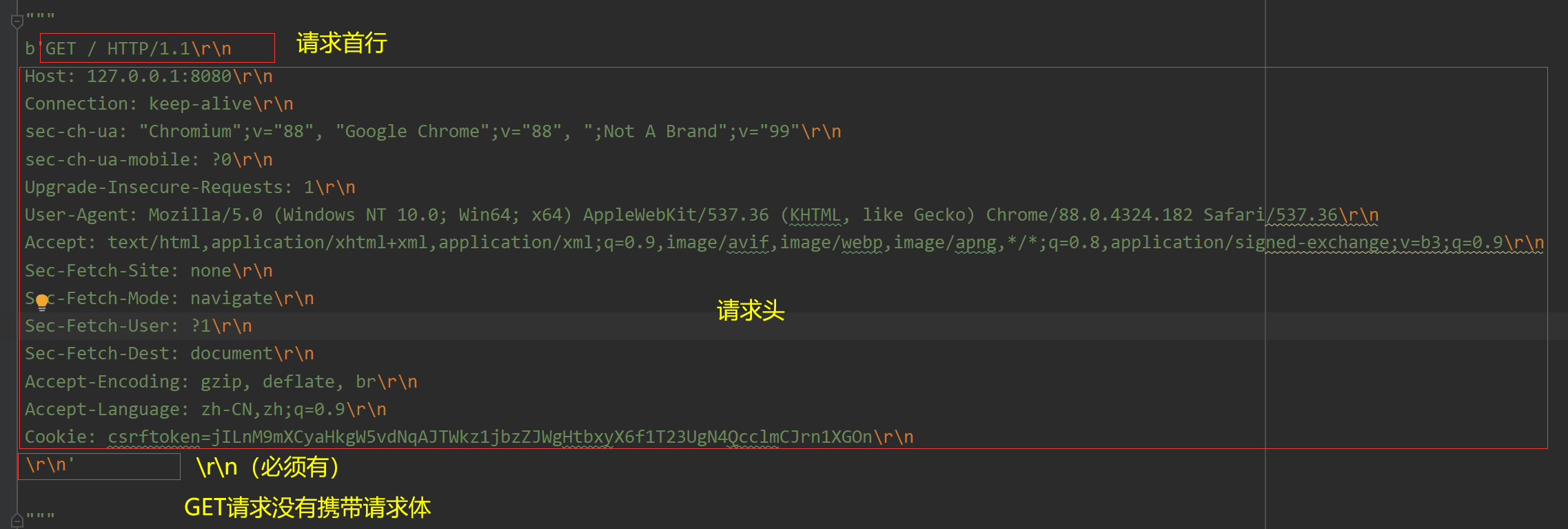
首先我们要分析一下,URL 的后缀名是放在请求数据的什么位置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 'GET /index HTTP/1.1\r\n' 'Host: 127.0.0.1:8080\r\n Connection: keep-alive\r\n sec-ch-ua: "Chromium";v="88", "Google Chrome";v="88", ";Not A Brand";v="99"\r\n sec-ch-ua-mobile: ?0\r\n Upgrade-Insecure-Requests: 1\r\n User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36\r\n Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9\r\n Sec-Fetch-Site: none\r\n Sec-Fetch-Mode: navigate\r\n Sec-Fetch-User: ?1\r\n Sec-Fetch-Dest: document\r\n Accept-Encoding: gzip, deflate, br\r\n Accept-Language: zh-CN,zh;q=0.9\r\n Cookie: csrftoken=jILnM9mXCyaHkgW5vdNqAJTWkz1jbzZJWgHtbxyX6f1T23UgN4QcclmCJrn1XGOn\r\n \r\n' 'GET /login HTTP/1.1\r\n' 'Host: 127.0.0.1:8080\r\n Connection: keep-alive\r\n sec-ch-ua: "Chromium";v="88", "Google Chrome";v="88", ";Not A Brand";v="99"\r\n sec-ch-ua-mobile: ?0\r\n Upgrade-Insecure-Requests: 1\r\n User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36\r\n Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9\r\n Sec-Fetch-Site: none\r\n Sec-Fetch-Mode: navigate\r\n Sec-Fetch-User: ?1\r\n Sec-Fetch-Dest: document\r\n Accept-Encoding: gzip, deflate, br\r\n Accept-Language: zh-CN,zh;q=0.9\r\n Cookie: csrftoken=jILnM9mXCyaHkgW5vdNqAJTWkz1jbzZJWgHtbxyX6f1T23UgN4QcclmCJrn1XGOn\r\n \r\n'
通过分析我们可以发现,其实 URL 的后缀就存放在请求数据的请求首行中,我们只需要解析请求数据就可以拿到后缀:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import socket"127.0.0.1" , 8080 ))5 )while True :1024 ).decode("utf-8" )" " )[1 ]b"HTTP/1.1 200 OK\r\n\r\n" )if current_path == "/index" :b"hello, old baby ~ Index" )elif current_path == "/login" :b"hello, old baby ~ Login" )elif current_path == "/register" :with open ("aaa.txt" , "rb" ) as f:else :b"hello, old baby ~" )
我们来测试一下:
访问 http://127.0.0.1:8080/index
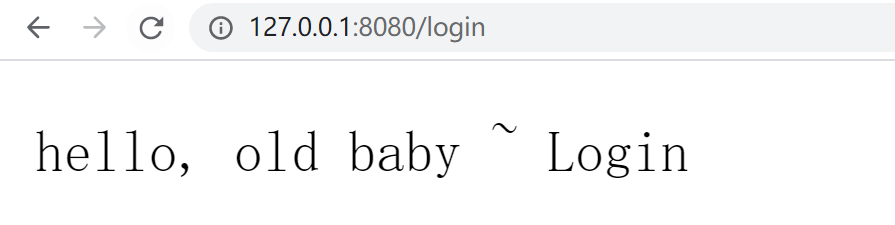
访问 http://127.0.0.1:8080/login
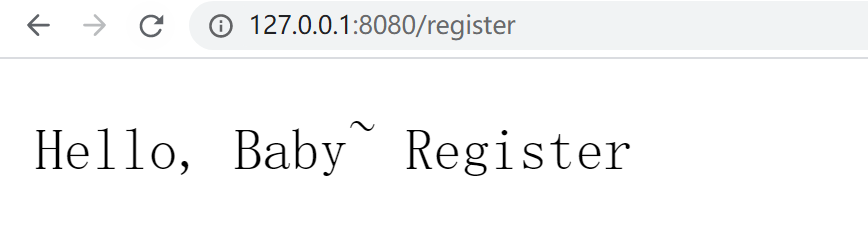
新建一个aaa.txt,随便写点什么内容,访问 http://127.0.0.1:8080/register
四、优化框架 为框架添加了路由识别的功能后,我们重新检视一下服务端的代码,发现还是有很多不足之处:
**代码重复:**建立服务端部分的套接字代码每次都需要编写;
**路由分析简单:**只能拿到路由的后缀,如果想拿到请求数据中的其他信息,还需要重复编写相关的数据解析代码;
**不支持并发:**服务端一次只能接收和处理一个请求。
当然,我们可以继续完善我们的逻辑,但是我们可以直接借助 wsgiref 内置模块来弥补上述不足。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from wsgiref.simple_server import make_serverdef run (env, response ):""" :param env: 请求所有相关的数据,wsgiref会自动处理好请求数据,封装成一个大字典 :param response: 响应相关的所有数据 :return: 返回给浏览器的数据 """ "200 OK" , [])return [b"hello~~" ]if __name__ == '__main__' :""" 会实时监听127.0.0.1:8080,只要客户端有请求过来,都会交给 run 函数去处理 """ "127.0.0.1" , 8080 , run)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from wsgiref.simple_server import make_serverdef run (env, response ):""" :param env: 请求所有相关的数据,wsgiref会自动处理好请求数据,封装成一个大字典 :param response: 响应相关的所有数据 :return: 返回给浏览器的数据 """ "200 OK" , [])"PATH_INFO" )if current_path == "/index" :return [b"hello, old baby ~ Index" ]elif current_path == "/login" :return [b"hello, old baby ~ Login" ]elif current_path == "/register" :with open ("aaa.txt" , "rb" ) as f:return [f.read()]return [b"404 error" ]if __name__ == '__main__' :""" 会实时监听127.0.0.1:8080,只要客户端有请求过来,都会交给 run 函数去处理 """ "127.0.0.1" , 8080 , run)
五、框架进一步封装 5.1 封装视图函数 在实际的开发中,服务端处理的业务逻辑是十分复杂的,所以判断完对应的路由后缀后进行的逻辑操作,最好能封装成对应的函数,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 from wsgiref.simple_server import make_serverdef index (env ): return [b"hello, old baby ~ Index" ]def login (env ):return [b"hello, old baby ~ Login" ]def register (env ):with open ("aaa.txt" , "rb" ) as f:return [f.read()]def error (env ):return [b"404 error" ]def run (env, response ):""" :param env: 请求所有相关的数据,wsgiref会自动处理好请求数据,封装成一个大字典 :param response: 响应相关的所有数据 :return: 返回给浏览器的数据 """ "200 OK" , [])"PATH_INFO" )if current_path == "/index" :elif current_path == "/login" :elif current_path == "/register" :if __name__ == '__main__' :""" 会实时监听127.0.0.1:8080,只要客户端有请求过来,都会交给 run 函数去处理 """ "127.0.0.1" , 8080 , run)
5.2 路由映射封装 如果服务端对应的路由,那么再通过 if-elif-else 的方式去判断路由后缀,会导致代码特别冗长。因此最好能有一个路由和其对应方法的映射表,直接通过映射关系找到对应的方法去执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 from wsgiref.simple_server import make_serverdef index (env ):return "hello, old baby ~ Index" def login (env ):return "hello, old baby ~ Login" def register (env ):with open ("aaa.txt" , "r" ) as f:return f.read()def error (env ):return "404 error" "/index" , index),"/login" , login),"/register" , register),"/error" , error),def run (env, response ):""" :param env: 请求所有相关的数据,wsgiref会自动处理好请求数据,封装成一个大字典 :param response: 响应相关的所有数据 :return: 返回给浏览器的数据 """ "200 OK" , [])"PATH_INFO" )None for url in urls:if current_path == url[0 ]:1 ]break if func:else :return [res.encode("utf-8" )]if __name__ == '__main__' :""" 会实时监听127.0.0.1:8080,只要客户端有请求过来,都会交给 run 函数去处理 """ "127.0.0.1" , 8080 , run)
5.3 框架拆分 我们进一步将框架拆分,将逻辑函数(也可以称为视图函数)全部放到新建的 views.py 中,将路由映射关系放到新建的 urls.py 中,最后的框架结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from wsgiref.simple_server import make_serverfrom .urls import urlsfrom .views import *def run (env, response ):""" :param env: 请求所有相关的数据,wsgiref会自动处理好请求数据,封装成一个大字典 :param response: 响应相关的所有数据 :return: 返回给浏览器的数据 """ "200 OK" , [])"PATH_INFO" )None for url in urls:if current_path == url[0 ]:1 ]break if func:else :return [res.encode("utf-8" )]if __name__ == '__main__' :""" 会实时监听127.0.0.1:8080,只要客户端有请求过来,都会交给 run 函数去处理 """ "127.0.0.1" , 8080 , run)
1 2 3 4 5 6 7 8 9 10 11 12 13 def index (env ):return "hello, old baby ~ Index" def login (env ):return "hello, old baby ~ Login" def register (env ):with open ("aaa.txt" , "r" ) as f:return f.read()def error (env ):return "404 error"
1 2 3 4 5 6 7 8 9 from .views import *"/index" , index),"/login" , login),"/register" , register),"/error" , error),
拆分之后的好处就是后期再添加新的接口需求,不需要再去修改 server.py 中的代码了,只需要在 urls.py 中新增路由和视图函数的映射关系,在 views.py 中编写对应的视图函数即可。例如,新增一个接口,返回一个 HTML 文件,就可以这么写:
新建一个 templates 文件夹,专门用于存放 .html 文件
1 2 3 4 5 6 7 8 9 10 from .views import *"/index" , index),"/login" , login),"/register" , register),"/error" , error),"/html" , html),
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def index (env ):return "hello, old baby ~ Index" def login (env ):return "hello, old baby ~ Login" def register (env ):with open ("aaa.txt" , "r" ) as f:return f.read()def error (env ):return "404 error" def html (env ):with open ("templates/hello.html" , "r" , encoding="utf-8" ) as f:return f.read()
六、模板语言初识 6.1 动静态网页的区别 动静态网页本质上都是前端页面,两者的区别为:
静态页面上的数据是写死的不会发生变化的
动态页面上的数据是实时变化的,数据是由服务端构造(从数据库中获取)返回的
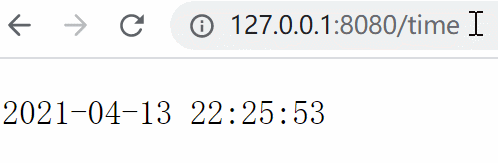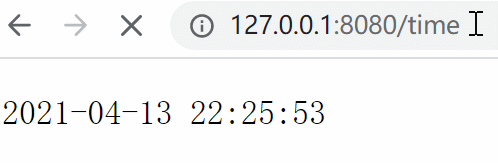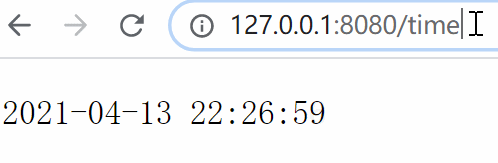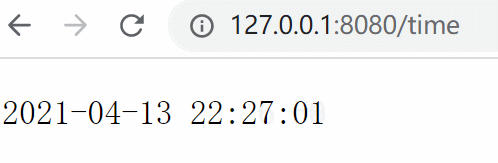
6.2 构造一个动态网页 我们来写一个接口,用于实时返回当前时间,模拟一个最简单的动态网页效果:
1 2 3 4 5 6 from views import *"/time" , get_time)
1 2 3 4 5 from datetime import datetimedef get_time (env ):return datetime.now().strftime("%Y-%m-%d %H:%M:%S" )
6.3 动态返回文件内容 想要实现动态的修改服务端中返回的文件的内容也是十分容易做到的,只是过程比较繁琐,如在框架的 templates 文件夹中有一个 index.html,现在想要根据访问路由后缀的不同返回不同的内容:
1 2 3 4 5 6 7 8 9 10 <!DOCTYPE html > <html lang ="en" > <head > <meta charset ="UTF-8" > <title > Title</title > </head > <body > <h1 > wait_to_replace</h1 > </body > </html >
1 2 3 4 5 6 7 8 from views import *"/index" , func),"/login" , func),"/register" , func),
1 2 3 4 5 6 7 8 9 10 def func (env ):"PATH_INFO" )with open ("templates/index.html" , "r" , encoding="utf-8" ) as f:"wait_to_replace" , f"hello, this is {current_path} " )return data
**难度提升:**如果服务端有一个字典类型的数据,如何才能在前端页面中便捷的使用呢?
6.4 Jinja2 的使用 Jinja2 模块中封装了大量的模板操作语法,极大的方便了我们开发过程中在前端操作渲染后端的数据,这边我们只是简单使用,后面会专门去窥探模板语言的用法。
1 2 3 4 5 6 7 8 9 10 11 12 from jinja2 import Templatedef func (env ):"name" : "cdc" , "age" : 25 , "hobby" : "sleep" }with open ("templates/index.html" , "r" , encoding="utf-8" ) as f:return res
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <!DOCTYPE html > <html lang ="en" > <head > <meta charset ="UTF-8" > <title > Title</title > </head > <body > <p > {{ user }}</p > <p > {{ user.name }}</p > <p > {{ user["name"] }}</p > <p > {{ user.get("name") }}</p > <p > </p > </body > </html >
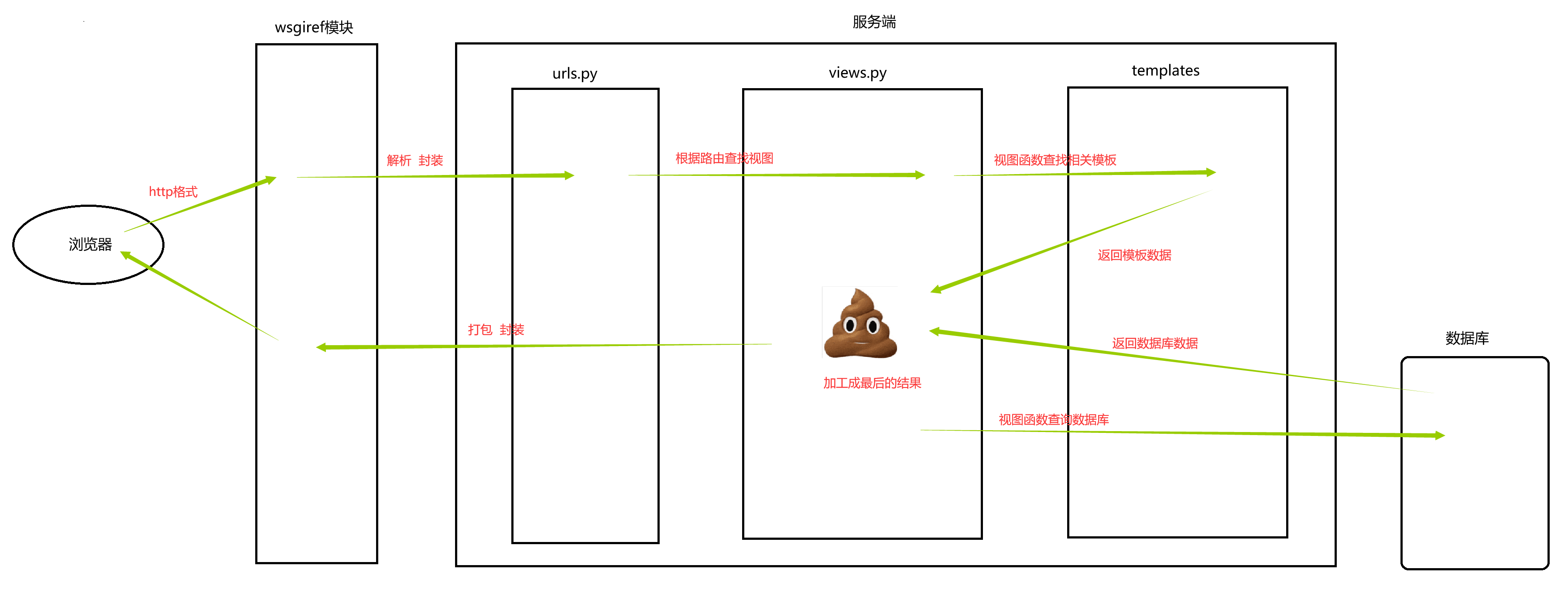
七、自定义框架生命周期 回顾一下我们自己手撸的框架,它的请求生命周期大致如下:
从我们自定义的框架中已经可以看到 Django 框架的影子了