属性 一、属性初识 我们定义一个用于计算圆的周长和面积的类:
1 2 3 4 5 6 7 8 9 10 11 12 13 class Circle :def __init__ (self, r ):self .r = rdef perimeter (self ):return 2 * 3.14 * self .rdef area (self ):return 3.14 * self .r ** 2 5 )print (c1.area()) print (c1.perimeter())
虽然功能实现了,但是在我们平时认知的逻辑上似乎不太合理。周长和面积都应该是圆的一个属性,换句话来说,周长和面积都应该是一个名字,而不应该是一个方法。我们在上述类中,实际上调用了计算周长和面积的方法,才得到的对应的值。我们可以使用面向对象的属性来实现这个操作。
**属性:**将方法伪装成一个属性,在代码的本质上没有实质上的提升,只是让逻辑看上去更加的合理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Circle :def __init__ (self, r ):self .r = r @property def perimeter (self ):return 2 * 3.14 * self .r @property def area (self ):return 3.14 * self .r ** 2 5 )print (c1.area) print (c1.perimeter)
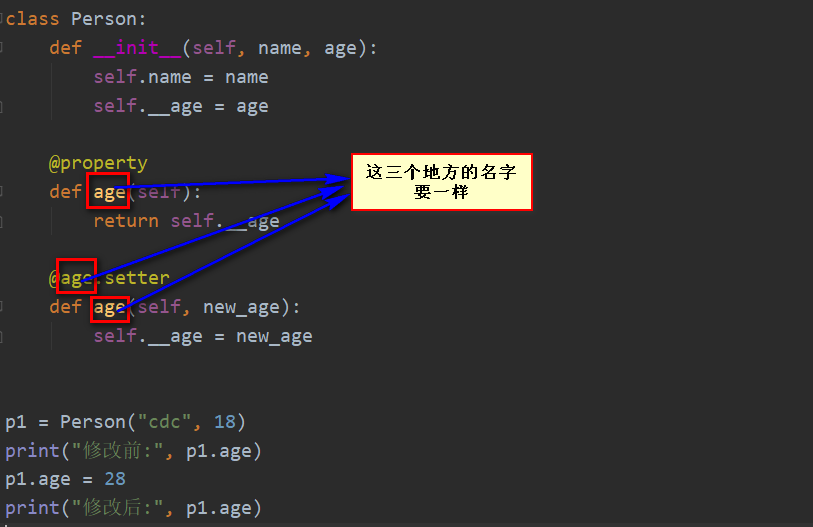
二、操作属性 虽然将方法伪装成属性后,调用属性和正常调用类中的其他属性一样,但是不能直接对其进行修改:
1 2 3 4 5 6 7 8 9 10 11 12 class Person :def __init__ (self, name, age ):self .name = nameself .__age = age @property def age (self ):return self .__age"cdc" , 18 )print (p1.age)28
我们可以通过 @方法名.setter 和 @方法名.deleter 对伪装的属性进行操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Person :def __init__ (self, name, age ):self .name = nameself .__age = age @property def age (self ):return self .__age @age.setter def age (self, new_age ):self .__age = new_age"cdc" , 18 )print ("修改前:" , p1.age)28 print ("修改后:" , p1.age)
注意:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Person :def __init__ (self, name, age ):self .name = nameself .__age = age @property def age (self ):return self .__age @age.deleter def age (self ):del self .__age"cdc" , 18 )print ("删除前:" , p1.age)del p1.ageprint ("删除后:" , p1.age)
三、属性的应用场景
一般用于类似周长、面积、BMI 等值的计算,需求上是想调用值,而实现上需要计算的场景。
涉及到私有相关的,这个时候更多的也会用到 setter 和 deleter
类方法和静态方法 一、类方法 类方法就是通过类名调用的方法。类方法中第一个参数约定俗称 cls,python 自动将类名(类空间)传给 cls。
1 2 3 4 5 6 7 8 9 class A :def func1 (self ):print (self ) @classmethod def func2 (cls ):print (cls)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class A :def func1 (self ):print (self ) @classmethod def func2 (cls ):print (cls) print (A) 111 )
对象也可以调用类方法,此时 cls 接收的是类本身
1 2 3 4 5 6 7 8 9 10 11 12 class A :def func1 (self ):print (self ) @classmethod def func2 (cls ):print (cls)
对于继承而言,cls 参数接收的也是调用类方法的类的空间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class A :def func1 (self ):print (self ) @classmethod def func2 (cls ):print (cls)class B (A ):pass
二、类方法的应用场景 1 2 3 4 5 6 7 8 9 class A1 :'cdc' 1 @classmethod def func1 (cls ): return cls.name + str (cls.count + 1 )print (A1.func1())
1 2 3 4 5 6 7 8 9 10 11 12 13 class A1:name = 'cdc' count = 1 name = "cdcx" # cls已经接收到了A1的空间了,可以按如下写name = "cdcx" print (A1.name )print (A1.name )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class A :"cdc" 18 @classmethod def func1 (cls ):print (cls) print (cls.name + str (cls.age))class B (A ):"tr" 28
此时,cls 参数接收到是子类 B 的空间,因此可以在父类中任意使用子类中的内容。当然,我们也可以不通过类方法,让父类的某个方法得到子类的类空间里面的任意值。
1 2 3 4 5 6 7 8 9 10 11 12 13 class A :12 def func2 (self ):print (self ) print (self .age) class B (A ):22 print (b1)
通过类方法和不通过类方法都可以实现,但是两种实现方式都有优劣之处。通过子类对象的方式,既可以拿到子类空间的内容也可以拿到子类实例化对象空间内的内容;通过类方法更加简单方便,所以具体的使用还是要看需求来定。
三、静态方法 静态方法是类中的函数,不需要实例,也是通过类名直接调用。静态方法主要是用来存放逻辑性的代码,逻辑上属于类,但是和类本身没有关系,也就是说在静态方法中,不会涉及到类中的属性和方法的操作。可以理解为,静态方法是个独立的、单纯的 函数,它仅仅托管于某个类的名称空间中,便于使用和维护。简单来说,静态方法和定义在类外部的普通函数没有区别,不需要对象和类的参与,定义静态方法只是为了让类更加整洁,避免打乱了逻辑关系,加强代码的复用性,方便以后代码维护。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class A :def func1 (self ):pass @classmethod def func2 (cls ):pass @staticmethod def func3 ():pass
1 2 3 4 5 6 7 8 9 10 class A : @staticmethod def login (username, pwd ):if username == "cdc" and pwd == "123456" :print ("登录成功" )else :print ("用户名或密码错误" )"cdc" , "123456" )
反射 反射就是用字符串数据类型的变量名来访问这个变量的值。
反射的方法有:
getattr
hasattr
setattr
delattr
一、类的反射 语法: getattr(类名(即名称空间),’XXX’) XXX一定是字符串,且在类中能找到同名的静态属性或者方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Student :"student" @classmethod def check_course (cls ):print ("查看课程" ) @staticmethod def login ():print ("登录" )print (Student.ROLE) print (getattr (Student, "ROLE" )) getattr (Student, "check_course" )() getattr (Student, "login" )()
二、对象的反射 语法:getattr(对象名(即实例化空间),’XXX’) XXX一定是字符串,且在类中能找到同名的方法或者对象的属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class A :def __init__ (self, name ):self .name = namedef func1 (self ):print (6666 )"cdc" )print (a1.name) print (getattr (a1, "name" )) getattr (a1, "func1" )()
三、模块的反射 语法:getattr(模块名,’XXX’) XXX一定是字符串,且在模块中能找到同名的方法或属性
1 2 3 4 5 import timegetattr (time, "sleep" )(3 ) print (666 )
四、反射的其他方法 hasattr 用于判断反射的调用者中是否有对应的方法或者属性,返回值是一个布尔值,一般都是和 getattr 联合使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Student :'STUDENT' @classmethod def check_course (cls ):print ('查看课程了' ) @staticmethod def login ():print ('登录' )print (getattr (Student, "age" )) print (hasattr (Student, "age" ))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Student :'STUDENT' @classmethod def check_course (cls ):print ('查看课程了' ) @staticmethod def login ():print ('登录' )if hasattr (Student, "age" ):print (getattr (Student, "age" ))else :print ("未找到该属性" )
setattr 用于修改反射调用者对应的属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Student :'STUDENT' @classmethod def check_course (cls ):print ('查看课程了' ) @staticmethod def login ():print ('登录' )print (Student.ROLE) setattr (Student, "ROLE" , "Teacher" )print (Student.ROLE)
delattr 用于删除反射调用者对应的属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Student :'STUDENT' @classmethod def check_course (cls ):print ('查看课程了' ) @staticmethod def login ():print ('登录' )print (Student.ROLE) delattr (Student, "ROLE" )print (Student.ROLE)
注:setattr 和delattr 也可以用于自定义的类、对象和模块,但是不建议用于他人编写的模块或类。
五、反射的好处 对于反射的作用,我们可能会有这样的疑问,对于我要调用的静态属性或者方法也好,我们都可以通过类名或者对象直接去调用,为什么还要多次一举来通过反射调用呢?使用反射到底有什么好处?我们可以通过一个简单的例子来感受一下
1 2 3 # 编写一个简单的学生选课系统,要求如下: # 1.通过用户的登录可以识别用户的身份,判断用户是学生还是管理员,并且根据身份实例化 # 2.根据每个身份对应的类,让用户选择能够做的事情
我们先按照我们正常的逻辑来写
1 2 3 4 123456 |Manager666 |Student2222 |Teacher
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 class Student :def __init__ (self, name ):self .name = namedef view_course (self ):print ("查看所有的课程" )def choose_course (self ):print ("选择课程" )def check_course (self ):print ("检查已选择过的课程" )class Manager :def __init__ (self, name ):self .name = namedef create_student (self ):print ('创建学生账号' )def create_course (self ):print ('创建课程' )def check_student_info (self ):print ('查看学生信息' )def login ():input ("用户名:" )input ("密码:" )with open ("user_info" , mode="r" , encoding="utf-8" ) as fr:for line in fr:"|" )if username == user and pwd == password:print ("登陆成功" )return username, idnt def main ():if idnt == "Student" :while True :input ("请输入操作:" )if exe_choice == "查看所有的课程" :elif exe_choice == "选择课程" :elif exe_choice == "检查已选择过的课程" :else :print ("没有此项操作" )else :while True :input ("请输入操作:" )if exe_choice == "创建学生账号" :elif exe_choice == "创建课程" :elif exe_choice == "查看学生信息" :else :print ("没有此项操作" )if __name__ == '__main__' :
我们可以看到,现在只有两个身份我们就需要做这么多的判断,对用户的身份需要判断,对用户的操作也需要判断,如果身份再增加的话,还需要继续添加判断的代码,整个项目就会特别的冗长。下面我们使用反射的思想的来对代码进行优化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 import sysclass Student :"查看所有的课程" , "view_course" ),"选择课程" , "choose_course" ),"检查已选择过的课程" , "check_course" )def __init__ (self, name ):self .name = namedef view_course (self ):print ("查看所有的课程" )def choose_course (self ):print ("选择课程" )def check_course (self ):print ("检查已选择过的课程" )class Manager :"创建学生账号" , "create_student" ),"创建课程" , "create_course" ),"查看学生信息" , "check_student_info" )def __init__ (self, name ):self .name = namedef create_student (self ):print ('创建学生账号' )def create_course (self ):print ('创建课程' )def check_student_info (self ):print ('查看学生信息' )def login ():input ("用户名:" )input ("密码:" )with open ("user_info" , mode="r" , encoding="utf-8" ) as fr:for line in fr:"|" )if username == user and pwd == password:print ("登陆成功" )return username, idntdef main ():print (user, idnt)'__main__' ] getattr (file, idnt) while True :for num, i in enumerate (operate_dic, 1 ):print (num, i)int (input ("请输入要执行的操操作序号:" ))1 ] if hasattr (obj, exe[1 ]):getattr (obj, exe[1 ])()else :print ("没有此操作" )if __name__ == '__main__' :
按照反射的思想来设计后,如果再添加新的类,也不需要对login和main函数进行修改了,只需要修改对应的类的定义就行了。
面向对象相关的内置函数
isinstance() 判断对象所属类型,包括继承关系
1 2 3 4 5 6 7 8 9 10 11 12 13 class A :pass class B :pass class C (A ):pass print (isinstance (a, A)) print (isinstance (b, A)) print (isinstance (c, C)) print (isinstance (c, A))
1 2 3 4 5 6 7 8 9 10 11 12 class A :pass class B (A ):pass print (isinstance (b, B)) print (type (b) is B) print (isinstance (b, A)) print (type (b) is A)
issubclass() 判断类与类之间的继承关系
1 2 3 4 class A :pass class B (A ):pass print (issubclass (B,A)) print (issubclass (A,B))
面向对象的内置方法 面向对象中的内置方法又称类中的特殊方法/双下方法/魔术方法,类中的每一个双下方法都有它自己的特殊意义,这些方法都不需要你在外部直接调用,而是通过一些特殊的语法来自动触发这些 双下方法。(注:内置函数和类的内置方法是有千丝万缕的关系的)
一、__call__ 实例化对象加(),就会触发该方法。call 方法常常用于在一个类中对另一个类的的功能进行添加,而不用去关注另一个类是如何定义的,flask框架源码中,很多地方就是使用的call方法
1 2 3 4 5 6 7 class A :def __call__ (self, *args, **kwargs ):return "调用了__call__方法" print (a) print (a())
1 2 3 4 5 6 7 8 9 10 11 12 class A :def __call__ (self, *args, **kwargs ):print (666 )class B :def __init__ (self, cls ):print ('在实例化A之前做一些事情' )self .a = cls()self .a()print ('在实例化A之后做一些事情' )
二、__len__ 1 2 3 4 5 6 7 8 9 10 11 12 13 class A : pass print (len (a)) class A :def __len__ (self ):return 666 print (len (a))
len(obj)相当于调用了这个obj的__len__方法
__len__方法return的值就是len函数的返回值,并不是真的返回对象的长度,具体的返回值需要自己来实现
如果一个obj对象没有__len__方法,那么len函数会报错
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class mylist :def __init__ (self ):self .lst = [1 , 2 , 3 , 4 , 5 , 6 ]self .name = 'alex' self .age = 83 def __len__ (self ):print ('执行__len__了' )return len (self .name) print (len (a))
三、__new__ 类中的构造方法,用于为实例化的对象开辟一个内存空间,在实例化对象之后和__init__执行之前执行。
1 2 3 4 5 6 7 8 class A :def __new__ (cls, *args, **kwargs ):print ("__new__方法" , 666 )def __init__ (self ):print ("__init__方法" , 777 )
我们之前定义类的时候,从来没有定义过__new__方法,但是为什么实例化对象时还能获得一块内存呢?这是因为所有的类都继承于object类,在object中实现了构造方法。因此,我们在自己定义类中的__new__的时候,可以直接调用父类object的__new__方法
1 2 3 4 5 6 7 8 9 10 class A :def __new__ (cls, *args, **kwargs ):super ().__new__(cls) print ("__new__方法" , 666 )return obj def __init__ (self ):print ("__init__方法" , 777 )
我们知道,对于同一个类,每次实例化时都会给对象开辟一个新的实例化空间,那我们有没有办法让所有的实例化对象只用一块空间内?
1 2 3 4 5 6 7 8 9 class A :pass print (a1) print (a2) print (a3)
单例类:如果一个类 从头到尾只能有一个实例,说明从头到尾之开辟了一块儿属于对象的空间,那么这个类就是一个单例类。单例类就可以用__new__方法来实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class A :None def __new__ (cls, *args, **kwargs ):if not cls.__SPACE:super ().__new__(cls)return cls.__SPACEdef __init__ (self, name, age ):self .name = nameself .age = age"cdc" , 18 )"trr" , 20 ) print (a1) print (a2) print (a1.name)
四、__str__
print一个对象相当于调用一个对象的__str__方法
str(obj),相当于执行obj.__str__方法
%s占位符字符串格式化输出时相当于执行obj.__str__方法
1 2 3 4 5 6 7 8 9 10 11 12 class A :def __init__ (self, name, age ):self .name = nameself .age = age"cdc" , 18 )print (a) print (str (a)) f"信息:{a} " print (s)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class A :def __init__ (self, name, age ):self .name = nameself .age = agedef __str__ (self ):return "姓名:%s,年龄:%s" % (self .name, self .age)"cdc" , 18 )print (a) print (str (a)) f"信息:{a} " print (s)
五、__repr__
repr(obj),相当于执行obj.__repr__方法
%r占位符格式化输出字符串时相当于执行obj.__repr__方法
1 2 3 4 5 6 7 8 9 10 class A :def __str__ (self ):return "__str__方法" def __repr__ (self ):return "__repr__方法" print (str (a),repr (a)) print ("----%s-----%r-----" % (a, a))
__repr__和__str__的关系:
__repr__是__str__的”备胎”,如果有__str__方法,那么print %s str 都先去执行__str__方法,并且使用__str__的返回值,如果没有__str__,那么 print %s str 都会执行__repr__
1 2 3 4 5 6 7 8 9 10 11 class A :def __str__ (self ):return "__str__方法" def __repr__ (self ):return "__repr__方法" print (a) print (str (a)) print ("%s" % a)
1 2 3 4 5 6 7 8 9 10 11 class A :def __repr__ (self ):return "__repr__方法" print (a) print (str (a)) print ("%s" % a)
在子类中使用__str__,先找子类的__str__,没有的话要向上找,只要父类不是object,就执行父类的__str__;但是如果除了object之外的父类都没有__str__方法,就执行子类的__repr__方法;如果子类也没有__repr__方法,还要向上继续找父类中的__repr__方法,一直找不到就再执行object类中的__str__方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 class A :def __str__ (self ):return "A中的__str__" def __repr__ (self ):return "A中的__repr__" class B (A ):def __str__ (self ):return "B中的__str__" def __repr__ (self ):return "B中的__repr__" print (b) class A :def __str__ (self ):return "A中的__str__" def __repr__ (self ):return "A中的__repr__" class B (A ):def __repr__ (self ):return "B中的__repr__" print (b) class A :def __repr__ (self ):return "A中的__repr__" class B (A ):def __repr__ (self ):return "B中的__repr__" print (b) class A :def __repr__ (self ):return "A中的__repr__" class B (A ):pass print (b)
六、__del__ __new__构造方法用于申请一块内存空间,__del__析构方法用于归还一些在创建对象的时候借用的资源(主要是操作系统资源,如文件资源和网络资源等),在释放空间操作之前执行。
简单来说,在类空间内定义的变量或者方法等资源,是由python解释器来管理的,当类空间释放掉以后,python的垃圾回收机制会自动回收这些资源。但是有些借用操作系统相关的资源,python解释器是无法去归还释放的。如:
1 2 3 4 5 6 7 8 9 10 class File :def __init__ (self, file_name ):self .file_name = file_nameself .f = open (self .file_name, mode="r" )def read (self ):self .f.read()"a.txt" )
f 定义在类内部的一个文件句柄资源,当整个代码运行结束后,f 就会被python解释器释放掉。但是操作系统借出的文件资源并不会因此释放掉,会驻存内存中,如果读取的文件的内容较多,实例化的对象也较多后,内存就会被过分占用导致系统卡顿现象,因此我们需要手动释放操作系统的文件资源。
1 2 3 4 5 6 7 8 9 10 11 12 13 class File :def __init__ (self, file_name ):self .file_name = file_nameself .f = open (self .file_name, mode="r" )def read (self ):self .f.read()def __del__ (self ):self .f.close() "a.txt" )
七、item系列 在内置模块中,有一些特殊的方法,要求对象必须实现__getitem__/__setitem__/__delitem__才能使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 class A :def __init__ (self, name ):self .name = namedef __getitem__ (self, item ):return self .namedef __setitem__ (self, key, value ):print (key) print (value) setattr (self , key, value)def __delitem__ (self, key ):del self .name"cdc" )print (a["name" ]) "name" ] = "trr" print (a.name)del a["name" ] class B :def __init__ (self,lst ):self .lst = lstdef __getitem__ (self, item ):return self .lst[item]def __setitem__ (self, key, value ):self .lst[key] = valuedef __delitem__ (self, key ):self .lst.pop(key)'111' ,'222' ,'ccc' ,'ddd' ])print (b.lst[0 ])print (b[0 ])3 ] = 'alex' print (b.lst)del b[2 ]print (b.lst)
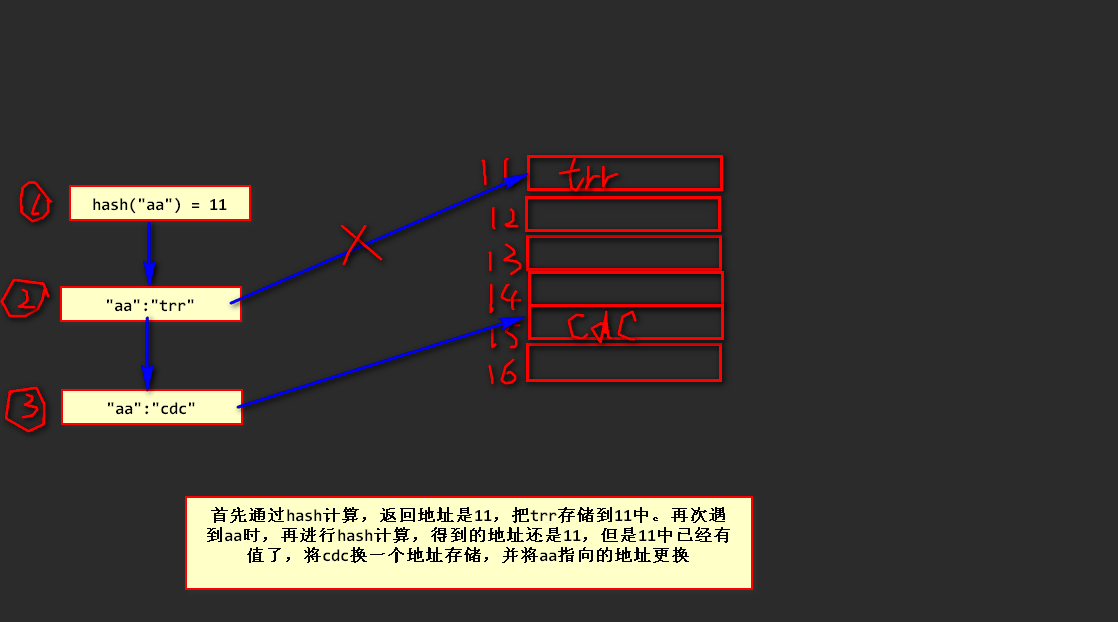
八、__hash__ hash算法:实现能够把某一个要存在内存里的值通过一系列计算,保证不同值的hash结果是不一样的。对同一个值在多次执行python代码的时候hash值是不同,但是对同一个值在同一次执行python代码的时候hash值永远不变。在存储数据时,hash 算法会先根据要存储的对象进行hash计算,得到一个数字,这个数字是真实的物理内存地址,理论上来说,在一次代码运行中,只要值不一样,得到的地址应该也不一样,但是hash算法也不是百分百保险的,也会出现值不同但是得到的地址相同的情况,为了防止这种情况的发生,hash算法实际上进行了以下步骤:
先看一下这个地址内是否已经有值存储,如果是空的,就将当前的数据存储进去;
如果地址中已经存储了值,就比较当前的值和已存储的值是否完全一样,如果一样就不操作,如果不一样,就会把要存储的值在换一个地址进行存储(二次寻址)。
hash算法常用于优化寻址操作。在python中最典型的应用就是字典的寻址和集合去重。
字典的寻址
在存储字典结构的数据类似时,会将每一对键值对的键进行hash计算,返回一个数字,这个数字就是实际的物理内存地址,然后将键值对的值的地址存放在对应的地址内。如果字典的键一样,后来的键对应的值就会把原来的值替换掉,即键每次寻址会找最新的那个地址(二次寻址)。取值时,将键再进行一次 hash 计算,直接去计算得出的内存地址处取值。
这就是为什么字典取值比列表快的原因,但是同时也要求了创建字典对象时,键必须是可hash的,且键要唯一。
1 2 dic = {"aa" :"trr" , "aa" :"cdc" }print (dic["aa" ])
集合的去重
集合去重也是运用了hash的机制,对每一个元素进行hash计算再去存储,对于值相等的元素对应的地址也相同,对应的值也相同,就不会重复存储了。
可以进行 hash(obj) 操作的对象,内部必须实现__hash__方法。
九、__eq__ 用于指定对象是否相等的规则
1 2 3 4 5 6 7 8 9 class A :def __init__ (self, name, age ):self .name = nameself .age = age"cdc" , 18 )"cdc" , 18 )print (a1 == a2)
如果想实现只要属性相同的两个对象就是同一个对象,我们可以这样做:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class A :def __init__ (self, name, age ):self .name = nameself .age = age"cdc" , 18 )"cdc" , 18 )def judge_obj (obj1, obj2 ):if obj1.name == obj2.name and obj1.age == obj2.age:return True else :return False print (judge_obj(a1, a2))
我们可以通过__eq__方法,将判断封装到类的内部
1 2 3 4 5 6 7 8 9 10 11 12 13 class A :def __init__ (self, name, age ):self .name = nameself .age = agedef __eq__ (self, other ):if self .name == other.name and self .age == other.age:return True "cdc" , 18 )"cdc" , 18 )print (a1 == a2)
十、__hash__ 和 __eq__ 联合使用 可哈希的集合(hashed collections),需要集合的元素实现了__eql__和__hash__,而这两个方法可以作一个形象的比喻:
哈希集合就是很多个桶,但每个桶里面只能放一个球。
__hash__函数的作用就是找到桶的位置,到底是几号桶。
__eql__函数的作用就是当桶里面已经有一个球了,但又来了一个球,它声称它也应该装进这个桶里面(__hash__函数给它说了桶的位置),双方僵持不下,那就得用__eql__函数来判断这两个球是不是相等的(equal),如果是判断是相等的,那么后来那个球就不应该放进桶里,哈希集合维持现状。
我们可以通过一个很重要的例子来深入了解一下:
1 现在又一个Person 类,该类有500个对象,对象有姓名,性别,年龄三个属性。现在我认为只要是年龄和性别相同的对象,就属于同一个对象,针对这个需求对500个对象进行去重。
首先我们先把类和对象实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Person :def __init__ (self, name, age, sex ):self .name = nameself .age = ageself .sex = sexlist () for i in range (1 , 101 ):"cdc" , i, "male" ))for i in range (1 , 101 ):"ctt" , i, "female" ))for i in range (1 , 101 ):"trr" , i, "female" ))for i in range (1 , 101 ):"th" , i, "male" ))for i in range (1 , 101 ):"lj" , i, "male" ))print (len (person_lst))
谈及到去重,我们的第一想法是尝试使用 set
1 print (set (person_lst)) # {<__main__.Person object at 0 x0000021BAB6C2048>, <__main__.Person object at 0 x0000021BAB6CA048>......}
理论上来说,能实现 set 的对象内部一定要实现__hash__方法,之所以没有报错是因为 object 类中为我们实现了,但是 object 中实现的 __hash__ 方法无法满足我们的需求,我们要自己实现一个
1 2 3 4 5 6 7 8 class Person :def __init__ (self, name, age, sex ):self .name = nameself .age = ageself .sex = sexdef __hash__ (self ):return f"{self.name} {self.sex} "
得到我们自己想要的hash值以后,我们还要规定一个判断新的值和已经存储的值是否相等的规则,否则当同一个地址下,新存入的对象和已存在的对象相遇,无法判断这两个对象是否相等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class Person :def __init__ (self, name, age, sex ):self .name = nameself .age = ageself .sex = sexdef __hash__ (self ):return hash (f"{self.name} {self.sex} " )def __eq__ (self, other ):if self .name == other.name and self .sex == other.sex:return True def __repr__ (self ):return f"姓名:{self.name} ,性别:{self.sex} " list () for i in range (1 , 101 ):"cdc" , i, "male" ))for i in range (1 , 101 ):"ctt" , i, "female" ))for i in range (1 , 101 ):"trr" , i, "female" ))for i in range (1 , 101 ):"th" , i, "male" ))for i in range (1 , 101 ):"lj" , i, "male" ))for i in set (person_lst):print (i)""" 姓名:th,性别:male 姓名:lj,性别:male 姓名:cdc,性别:male 姓名:ctt,性别:female 姓名:trr,性别:female """