常用内置函数概览
https://www.processon.com/mindmap/5e2ea3e6e4b0d27af181882c
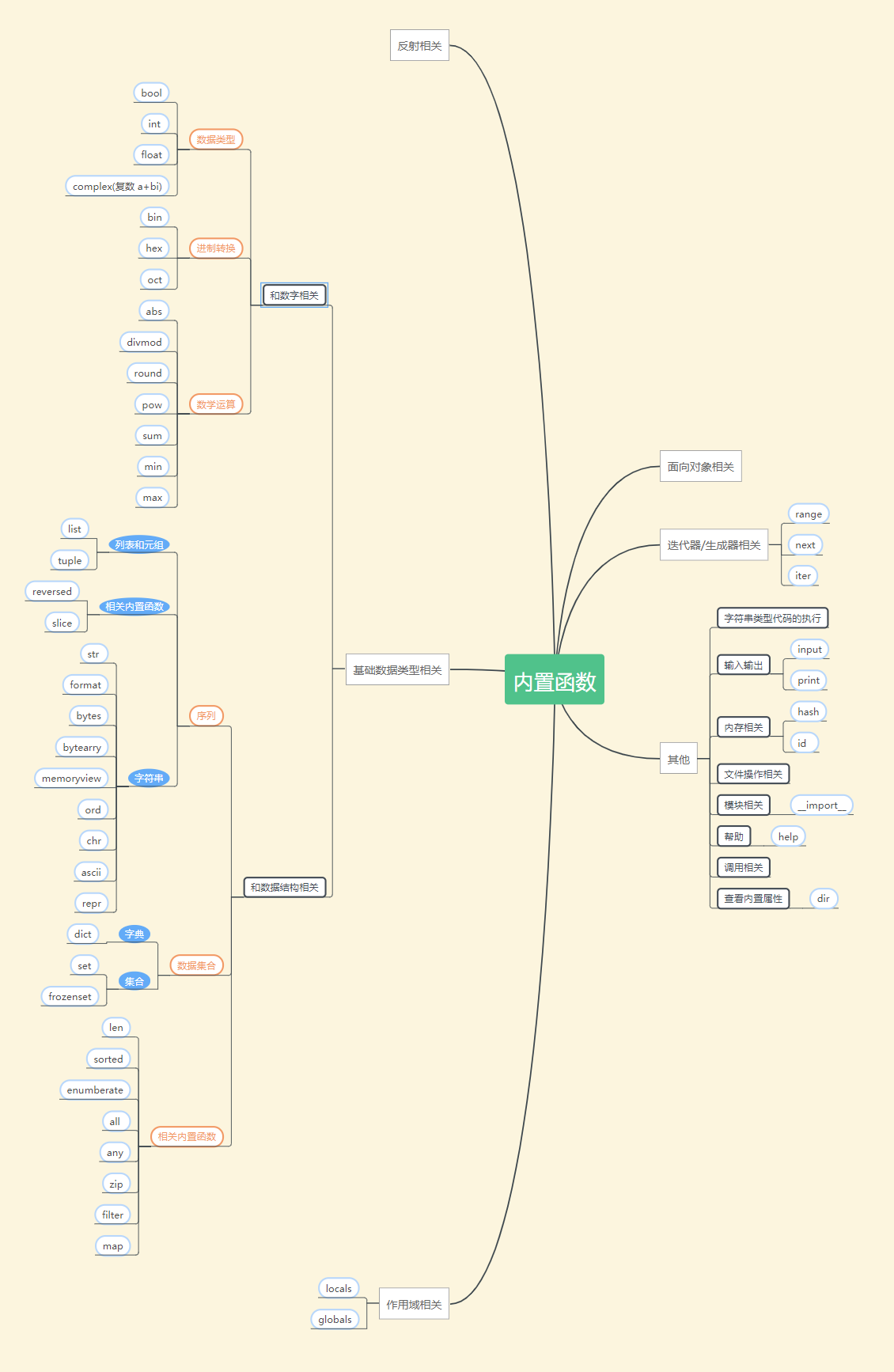
作用域相关
locals 和 globals
- locals:函数会以字典的类型返回当前位置的全部的局部变量
- globals:函数会以字典的类型返回全部的全局变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| a = 10
def func():
a = 40
b = 20
def abc():
print("哈哈")
print(a, b)
print(globals())
print(locals())
func()
print(globals())
print(locals())
|
迭代器/生成器相关
一、range
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| for i in range(0,5):
print(i)
for i in range(0,10,3):
print(i)
for i in range(10, 0, -3):
print(i)
|
二、iter
1
2
3
4
5
6
7
8
| lst = ["aa", "bb", "cc", "dd"]
it = iter(lst)
print(it.__next__())
print(it.__next__())
print(it.__next__())
print(it.__next__())
|
三、next
1
2
3
4
5
6
| lst = ["aa", "bb", "cc", "dd"]
it = lst.__iter__()
print(it.__next__())
print(next(it))
print(next(it))
print(next(it))
|
输入输出
一、print
1
2
3
4
5
6
7
8
9
10
11
|
print("aaa")
print("aaa", "bbb", "ccc")
print("aaa", "bbb", "ccc", sep="_")
print("aaa", "bbb", "ccc", end="*****")
print("ddd")
|
1
2
3
|
name = input("姓名:")
print(name)
|
内存相关
一、id
1
2
3
4
5
|
a = 1111
b = "aaaaa"
print(id(a))
print(id(b))
|
二、hash
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
tup = (1, 2, 3)
print(hash(tup))
s = "呵呵"
print(hash(s))
n = 111
print(hash(n))
dct = {"a": "aaa"}
print(hash(dct))
lst = [1, 2, 3]
print(hash(lst))
st = {1, 2, 3}
print(hash(st))
|
模块相关
1
2
3
4
5
|
name = input("要调用的模块")
__import__(name)
|
进制转换
1
2
3
4
| a = 10
print(bin(a))
print(hex(a))
print(oct(a))
|
调用相关
callable
用于判断变量是否可调用
1
2
3
4
5
6
7
| a = 10
print(callable(a))
def func():
print("aaa")
print(callable(func))
|
字符串类型代码的执行
一、eval
1
2
3
4
|
s = "3+5+9"
print(s)
print(eval(s))
|
二、exec
1
2
3
4
5
6
7
|
code = "for i in range(0,10):print(i)"
exec(code)
exec("""def func():print("我是cdc")""")
func()
|
三、compile
代码的执行过程:python解释器将代码编译成字节码 –> 字节码传到操作系统中进行识别 –> 操作系统调动相关的硬件进行功能的实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
'''参数说明 :
1. resource 要执行的代码,动态代码片段
2. 文件名 代码存放的文件名,当传⼊了第⼀个参数的时候,这个参数给空就可以了
3. 模式,取值有 3 个:
3.1 exec: 一般放⼀些流程语句的时候
3.2 eval: resource 只存放一个求值表达式
3.3 single: resource 存放的代码有交互的时候mode应为single
'''
code1 = "for i in range(10): print(i)"
c1 = compile(code1, "", mode="exec")
exec(c1)
code2 = "1+2+3"
c2 = compile(code2, "", mode="eval")
a = eval(c2)
print(a)
code3 = "name = input('请输⼊入你的名字:')"
c3 = compile(code3, "", mode="single")
exec(c3)
print(name)
|
使用compile的好处:
- 可以防止源码泄露,编译后都是字节码,只有操作系统可以识别
- 加快运行速度。不用读一行解释一行再编译一行,可将代码先全部编译成字节码,后期可直接运行(python 的 pypy 解释器就是这个原理)
数学运算相关
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
print(abs(-2))
print(divmod(10, 3))
print(sum([1, 2, 3, 4, 5]))
print(max([1, 2, 3, 4, 5]))
print(min([1, 2, 3, 4, 5]))
print(pow(10, 2))
print(pow(10, 2, 3))
print(round(4.5))
print(round(4.6))
print(round(5.5))
print(round(5.6))
|
序列相关
一、reversed
1
2
3
4
5
6
7
8
9
10
| lst = ["aa", 1, 21, "cc"]
print(reversed(lst))
print(lst)
new_lst = list(reversed(lst))
print(new_lst)
s = "abcdefg"
new_a = list(reversed(s))
print(new_a)
|
二、slice
1
2
3
4
5
| lst = [1, 2, 3, 4, 5, 6, 7]
print(lst[1:5:2])
s = slice(1, 5, 2)
print(lst[s])
|
字符串相关
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
s = "我叫cdc"
print(format(s, "^20"))
print(format(s, "<20"))
print(format(s, ">20"))
print(format(3, 'b'))
print(format(97, 'c'))
print(format(11, 'd'))
print(format(11, 'o'))
print(format(11, 'x'))
print(format(11, 'X'))
print(format(11, 'n'))
print(format(11))
print(format(123456789, 'e'))
print(format(123456789, '0.2e'))
print(format(123456789, '0.2E'))
print(format(1.23456789, 'f'))
print(format(1.23456789, '0.2f'))
print(format(1.23456789, '0.10f'))
print(format(1.23456789e+3, 'F'))
|
二、bytes 和 bytearry
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| s = "你好啊"
a = s.encode("utf-8")
print(a)
print(a.decode("utf-8"))
bs = bytes("你好啊", encoding="utf-8")
print(bs.decode("utf-8"))
ret = bytearray("cdc", encoding='utf-8')
print(ret[0])
ret[0] = 65
print(str(ret))
s = memoryview("cdc".encode("utf-8"))
print(s)
|
三、ord chr ascii
1
2
3
4
5
6
7
8
9
| print(ord('a'))
print(ord('中'))
print(chr(65))
print(chr(20018))
print(ascii("a"))
print(ascii("房"))
|
四、repr
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| name = "你好. \n我是cdc"
print(name)
"""
你好.
我是cdc
"""
print(repr(name))
name2 = "你好. \n我叫%s" % "cdc"
print(name2)
"""
你好.
我叫cdc
"""
print(repr(name2))
|
其余内置方法
一、enumerate 枚举
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| lst = ["蛋1", "蛋2", "蛋3", "蛋4"]
for i in range(len(lst)):
print(i)
print(lst[i])
for index, el in enumerate(lst, 100):
print(index)
print(el)
"""
100
蛋1
101
蛋2
102
蛋3
103
蛋4
"""
|
二、all any
1
2
3
4
5
|
print(all([1, "哈哈", "馒头", True]))
print(any([0, "哈哈", "馒头", True]))
|
三、zip
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
lst1 = ["a", "b", "c", "d"]
lst2 = ["aa", "bb", "cc", "dd"]
lst3 = ["aaa", "bbb", "ccc", "ddd", "eee"]
for el in zip(lst1, lst2, lst3):
print(el)
"""
('a', 'aa', 'aaa')
('b', 'bb', 'bbb')
('c', 'cc', 'ccc')
('d', 'dd', 'ddd')
"""
|
四、sorted
语法:sorted(Iterable, key=None, reverse=False)
参数:
- Iterable:可迭代对象
- key:排序规则(排序函数),在 sorted 内部会将可迭代对象中的每⼀个元素传递给这个函数的参数,根据函数运算的结果进行排序
- reverse:是否是倒序,True–>倒序,False–>正序
1
2
3
4
5
6
7
8
| lst = [1,5,3,4,6]
lst2 = sorted(lst)
print(lst)
print(lst2)
dic = {1:'A', 3:'C', 2:'B'}
print(sorted(dic))
|
和函数组合使用,函数返回的必须是一个数字,用于排序
1
2
3
4
5
6
7
8
|
lst = ["钢铁侠", "银河护卫队", "美国队长", "蜘蛛侠", "复仇者联盟"]
def func(s):
return len(s)
print(sorted(lst, key=func))
|
和匿名函数组合使用
1
2
3
4
5
6
7
8
9
10
11
12
|
lst = ["钢铁侠", "银河护卫队", "美国队长", "蜘蛛侠", "复仇者联盟"]
print(sorted(lst, key=lambda s: len(s)))
lst = [{"id": 1, "name": 'alex', "age": 18},
{"id": 2, "name": 'wusir', "age": 16},
{"id": 3, "name": 'taibai', "age": 17}]
print(sorted(lst, key=lambda e: e['age']))
|
五、filter
语法:filter(function. Iterable)
参数:
- function:用来筛选的函数,在 filter 中会自动的把 iterable 中的元素逐个传递给 function,然后根据function 返回的 True 或者 False 来判断是否保留此项数据;
- Iterable:可迭代对象
1
2
3
4
5
6
7
8
9
10
| lst = [1,2,3,4,5,6,7]
ll = filter(lambda x: x%2==0, lst)
print(ll)
print(list(ll))
lst = [{"id": 1, "name": 'alex', "age": 18},
{"id": 2, "name": 'wusir', "age": 16},
{"id": 3, "name": 'taibai', "age": 17}]
fl = filter(lambda e: e['age'] > 16, lst)
print(list(fl))
|
六、map
语法:map(function, iterable)
参数:
- function 将可迭代对象中每一个元素去function中执行并返回结果
- iterable 可迭代对象
1
2
3
4
5
6
|
def func(e):
return e*e
mp = map(func, [1, 2, 3, 4, 5])
print(mp)
print(list(mp))
|
改写成匿名函数
1
| print(list(map(lambda x: x * x, [1, 2, 3, 4, 5])))
|
如果函数中有多个参数,后面的列表要一一对应;如果列表长度不一样,以最短的列表为准
1
2
3
| lst1 = [1, 2, 3, 4, 5]
lst2 = [2, 4, 6, 8]
print(list(map(lambda x, y: x + y, lst1, lst2)))
|