Python 函数
函数相关思维导图
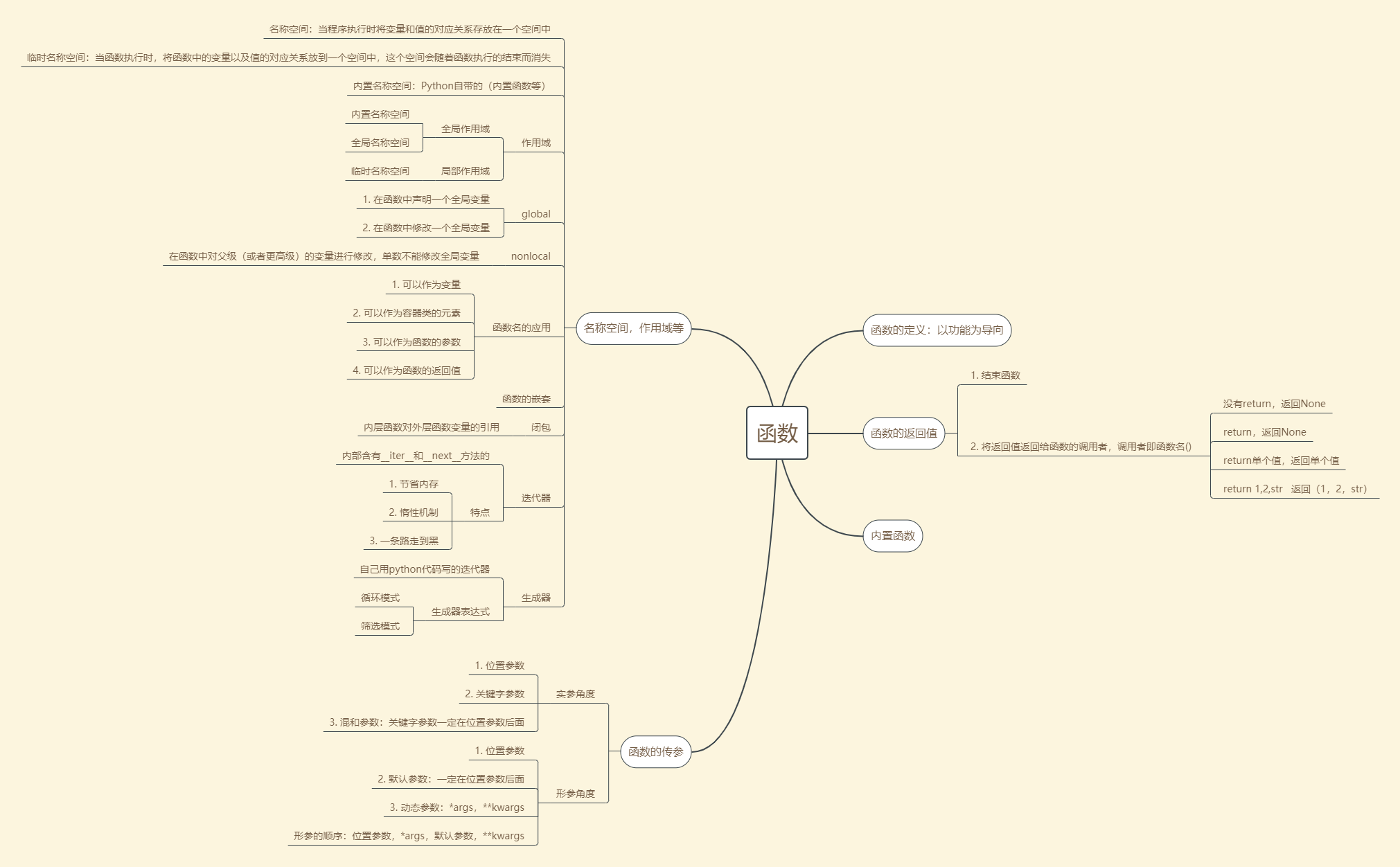
https://www.processon.com/mindmap/5e327935e4b096de64c9bc3f
函数简介
一、什么是函数
函数是对代码块或功能的封装和定义。
函数必须先定义,再使用。可以形象的将函数理解为一个工具,我们必须先把要用的工具找齐准备好,这样等到我们要用工具的时候就可以直接拿来用。
在函数定义阶段中,只检测语法,不执行代码,即语法错误在函数定义阶段就会检测出来,而代码的逻辑错误只有在执行时才会知道。
二、为什么要使用函数
1 | |
在上述制造汽车的例子中,我们的代码都是从上而下顺序执行的。当需要制作几辆汽车时,就需要把整个流程重复执行几次;并且当我们需要修改某一步骤时,又要把所有相关的代码部分统统修改。因此,不使用函数去管理代码,便会存在以下的问题:
- 代码的组织结构不够清晰,可读性差;
- 遇到重复的功能只能重复编写实现代码,代码冗余;
- 功能需要扩展时,需要找出所有实现该功能的地方修改之,无法统一管理且维护难度极大。
三、函数的分类和定义
- 内置函数:为了方便我们的开发,针对一些简单的功能,python 解释器已经为我们定义好了的函数即内置函数。对于内置函数,我们可以拿来就用而无需事先定义,如 len(),sum(),max()
- 自定义函数:内置函数所能提供的功能是有限的,我们自己需要根据需求,事先定制好我们自己的函数来实现某种功能。
1 | |
注:函数并不一定都要指定返回值。函数如果没有显示指定返回值(即函数定义中没有写 return 或者 return语句后没有值),默认返回 None。
1 | |
调用函数
1 | |
函数的参数
一、实参和形参
- 形参(形式参数)是在定义函数时,括号内声明的参数。形参的本质是一个变量名,用于接收外部传进来的值;
- 实参(实际参数)是在调用函数时,括号内传入的值,实参可以是变量、常量、表达式或者三者的组合
- 在调用有参函数时,实参(值)会赋值给形参(变量名)。在python中,变量名和值只是单纯的绑定关系,而对于函数来说,这种关系只在调用时生效,在调用后就解除。
二、形参的具体使用
2.1 位置参数
- 位置参数,即按顺序定义的参数
- 在定义函数时,按照从左往右定义的形式参数称为位置形参,凡是按照这种形式定义的形参都必须被传值
- 在调用函数时,按照从左往右传入的实际参数称为位置实参,凡是按照这种形式定义的实参会跟形参一一对应
1 | |
2.2 关键字参数
- 调用函数时,实参也可以是键值对方式传入,称为关键字参数,可以不按照从左往右的顺序传入,但是也能为对应的形参赋值
- 当实参是位置参数和关键字参数混合使用时,要保证关键字参数在位置参数后面,且不能对一个形参重复赋值
1 | |
2.3 默认参数
- 在定义函数时就已经为形参赋值,这类形参称为默认参数
- 在函数调用时,若不给默认参数重新赋值,则默认参数就使用默认的值,否则使用新的赋值
- 默认参数必须在位置参数之后
- 默认参数的值通过应该设置为不可变类型
1 | |
可变长位置参数
当调用函数时,传入的位置实参个数多于位置形参个数时,就会报溢出错误。可变长位置参数就是为了解决此类问题。如果在最后一个形参前加*号,溢出的位置参数都会被该形参接收,并以元组形式保存。
1 | |
1 | |
1 | |
可边长关键字参数
如果在最后一个形参前加 ** 号,所有溢出的关键字参数都会被该形参接收,并以字典的形式保存
1 | |
1 | |
命名关键字参数
当函数调用者将关键字参数放入
**kwargs中进行传参,我们又想知道我们需要的关键字参数是否被包含在了可变长关键字参数内,我们还需要对接收的值进一步判断,增加了代码的复杂度
1 | |
因此,为限定函数调用者必须对必要的关键字参数进行传值,python3 提供了命名关键字参数。
在定义形参时,用 * 作为一个分割符号,* 之后的形参称为命名关键字参数。对于这类参数,进行函数调用的时候,必须以key=value的形式进行传值,且必须被传值
1 | |
命名关键字参数也可以有默认值
1 | |
注意:sex不是默认参数,height也不是位置参数,两者都是命名关键字参数,”male”只是sex的默认值,因此即便将 sex放置在 height 前面也不会有问题(按照正常的逻辑,位置参数必须在默认参数前面,但是sex和height都是命名关键字参数,因此不需要遵守这个规则)
如果形参中已经有 *args 了,命名关键字参数就不需要一个单独的 * 来作为分隔符了
1 | |
组合使用
定义时各类形参的顺序:位置参数、默认参数、
*args、命名关键字参数、**kwargs
命名空间和作用域
一、命名空间
在 python 解释器开始执行之后,就会在内存中开辟一个空间,每当遇到一个变量的时候,就把变量名和值之间的关系记录下来;当遇到函数定义的时候,解释器只是把函数名读入内存,表示这个函数存在了,至于函数内部的变量和逻辑,解释器是不关心的。即一开始的时候函数只是加载进来,只有当函数被调⽤和访问的时候,解释器才会根据函数内部声明的变量来进行开辟变量的内部空间。随着函数执行完毕,这些函数内部变量占用的空间也会随着函数执行完毕而被清空。

存放名字和值对应关系的空间叫命名空间,在python中,一共有三种命名空间:
- 内置命名空间:存放python解释器为我们提供的名字,如 print,list,tuple,str 等
- 全局命名空间:函数外部声明的变量和最外层的函数均属于全局命名空间
- 局部命名空间:函数内部定义的变量和内部定义的函数均属于局部命名空间,局部命名空间之间相互独立
1 | |
命名空间加载顺序:内置命名空间 –> 全局命名空间 –> 局部命名空间
上述的例子中,当python解释器开始运行时,先会加载 print 等python解释器内置的命名空间,接着再从上到下加载全局名称空间(变量a和函数名 func),当执行函数时,最后再为函数内部的变量和嵌套的函数开辟命名空间,即最后加载局部命名空间
命名空间的取值顺序:局部命名空间 –> 全局命名空间 –> 内置命名空间(就近原则)
1 | |
上述例子中,函数内部的 print(a) 会先在当前的局部命名空间中查找a,如果查找不到就会往全局命名空间中查找;对于 print 函数,现在 func 函数的局部命名空间查找,查找不到就往全局命名空间查找,还是查找不到函数的定义和声明,就会往 python 解释器的内置命名空间进行查找。
二、作用域
**作用域:**作用域就是作用范围,按照生效范围来看分为全局作用域和局部作用域
- 全局作用域:包含内置命名空间和全局命名空间,在整个文件的任何位置都可以使用(遵循从上到下逐行执行)
- 局部作用域:在函数内部可以使用
作用域命名空间
- 全局作用域:全局命名空间 + 内置命名空间
- 局部作用域:局部命名空间
我们可以通过 globals() 函数来查看全局作用域中的内容, 也可以通过 locals() 来查看局部作用域中的变量和函数信息
1 | |
关键字global和nonlocal
一、global
global 表示不再使用局部作用域中的内容, 而改用全局作用域中的变量。当在局部作用域中改变了该变量的值,则全局中该变量的值也会发生改变。
1 | |
二、nonlocal
nonlocal 表示在 局部作用域 中,调用命名空间中最近的变量(即若父级函数中查找不到,继续往父级的父级查找)。如果在子函数中修改了该变量,则原来作用域中的该变量的值也会发生响应的变化。
1 | |
匿名函数
匿名函数是为了解决一些简单的需求而设计的一句话函数,用lambda关键字来声明,不需要用def来声明。
语法: 函数名 = lambda 参数: 返回值
1 | |
注意:
- 函数的参数可以有多个,多个参数之间⽤逗号隔开
- 匿名函数不管多复杂,只能写⼀行, 且逻辑结束后直接返回数据
- 返回值和正常的函数一样,可以是任意数据类型
- 匿名函数并不是说⼀定没有名字,这里前⾯的变量就是⼀个函数名。说他是匿名原因是通过__name__查看的时候,函数是没有名字的,统⼀都叫 lambda。在调用的时候没有什么特别之处,像正常的函数调用即可。
递归
- 递归函数就是函数在内部调用自己,必须的有递归的出口,否则会就是死循环
- 在python中递归的最大深度是998层
- 递归主要用于遍历树形结构
1 | |
1 | |
为什么要限制递归的深度?我们来观察以下两段代码:
1 | |
while 死循环重复使用的是同一个变量,因此不会对内存造成影响;而递归由于每次都是调用一个函数,每次都会为新函数中的变量开辟新的内存,如果不限制递归的深度,很容易造成内存的崩溃。且如果一个功能使得递归的深度过大,其实也表示该功能不太适合用递归实现。
1 | |